在當(dāng)今瞬息萬變的電商市場,尤其是二手交易平臺閑魚,每秒都可能產(chǎn)生海量的用戶行為、商品更新、交易動態(tài)和聊天消息。要實(shí)時處理這些每秒千萬級的數(shù)據(jù)洪流,并為推薦、風(fēng)控、搜索、監(jiān)控等核心業(yè)務(wù)提供即時洞察,背后是一套極其復(fù)雜、高性能、高可用的實(shí)時數(shù)據(jù)處理服務(wù)體系。閑魚的實(shí)現(xiàn),是阿里集團(tuán)多年大數(shù)據(jù)技術(shù)積淀與業(yè)務(wù)場景深度結(jié)合的典范。
一、 數(shù)據(jù)洪流的源頭:統(tǒng)一采集與接入
一切始于數(shù)據(jù)的產(chǎn)生。閑魚的實(shí)時數(shù)據(jù)源極其多樣:
- 用戶行為日志:點(diǎn)擊、瀏覽、搜索、收藏、聊天等,通過埋點(diǎn)SDK收集。
- 業(yè)務(wù)數(shù)據(jù)庫變更:商品發(fā)布、價格修改、訂單狀態(tài)更新等,通過阿里巴巴開源的Canal(基于數(shù)據(jù)庫binlog的增量訂閱與消費(fèi)組件)實(shí)時捕獲MySQL的變更日志。
- 消息中間件:各類系統(tǒng)間的異步消息,如交易成功通知。
這些數(shù)據(jù)首先被統(tǒng)一接入到阿里云SLS(日志服務(wù))或Apache Kafka這類高吞吐、低延遲的消息隊列中。這一步的關(guān)鍵是輕量級、高并發(fā)、保序的客戶端采集Agent,以及服務(wù)端強(qiáng)大的分區(qū)(Partition)擴(kuò)展能力,通過水平分片將每秒千萬級的數(shù)據(jù)流分散到數(shù)百甚至上千個分區(qū)中并行處理,避免單點(diǎn)瓶頸。
二、 核心引擎:流計算平臺的選型與優(yōu)化
這是實(shí)時處理的“大腦”。閑魚經(jīng)歷了從自研到擁抱開源,再到深度定制優(yōu)化的演進(jìn)。目前其核心是 Apache Flink,一個高性能、高可靠、精確一次(Exactly-Once)語義的流處理框架。
為何選擇Flink?
- 低延遲與高吞吐的完美平衡:其基于流水線的執(zhí)行模型,而非微批處理,使得數(shù)據(jù)處理延遲可低至毫秒級,同時吞吐量極大。
- 狀態(tài)管理:內(nèi)置強(qiáng)大的狀態(tài)后端(如RocksDB),可以高效管理窗口聚合、用戶畫像實(shí)時更新等需要記住歷史數(shù)據(jù)的計算。
- 事件時間與亂序處理:支持基于事件時間(Event Time)的窗口計算,并能通過水位線(Watermark)機(jī)制處理網(wǎng)絡(luò)延遲導(dǎo)致的數(shù)據(jù)亂序,這對精準(zhǔn)統(tǒng)計(如每分鐘交易額)至關(guān)重要。
閑魚團(tuán)隊對Flink進(jìn)行了大量深度優(yōu)化:
- 資源調(diào)度:與阿里云K8s、Flink on Yarn深度集成,實(shí)現(xiàn)動態(tài)擴(kuò)縮容,在“雙11”等大促期間秒級擴(kuò)容數(shù)千個計算核心。
- 狀態(tài)后端優(yōu)化:針對RocksDB進(jìn)行參數(shù)調(diào)優(yōu),并探索新型狀態(tài)后端以降低訪問延遲。
- SQL化與平臺化:提供Flink SQL開發(fā)界面,讓業(yè)務(wù)開發(fā)人員能更專注于邏輯而非底層API,提升開發(fā)效率。
三、 架構(gòu)全景:分層與協(xié)同
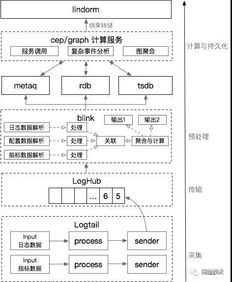
閑魚的實(shí)時數(shù)據(jù)處理服務(wù)并非單一系統(tǒng),而是一個分層協(xié)同的體系:
- 實(shí)時計算層(Flink Jobs集群):
- 實(shí)時ETL:對原始數(shù)據(jù)進(jìn)行清洗、格式化、維度關(guān)聯(lián)(如將商品ID關(guān)聯(lián)到類目、賣家信息),輸出結(jié)構(gòu)化的實(shí)時數(shù)據(jù)流。
- 實(shí)時聚合:進(jìn)行秒/分鐘級別的窗口聚合,如實(shí)時GMV大盤、熱門商品排行、地域分布熱力圖。
- 復(fù)雜事件處理(CEP):用于實(shí)時風(fēng)控,例如識別“短時間內(nèi)發(fā)布大量相似商品”的欺詐模式。
- 實(shí)時特征計算:為推薦和搜索引擎提供用戶實(shí)時興趣向量、商品實(shí)時熱度分等。
- 實(shí)時存儲與查詢層:計算結(jié)果需要被快速存儲和訪問。
- 高性能KV存儲:如 阿里云Tair(Redis企業(yè)版) 或 HBase,用于存儲實(shí)時畫像、模型特征、計數(shù)(如商品瀏覽量)。它們提供亞毫秒級的讀寫能力。
- 實(shí)時OLAP數(shù)據(jù)庫:如 Apache Druid 或 ClickHouse,用于存儲聚合后的時間序列數(shù)據(jù),支持業(yè)務(wù)人員通過BI工具進(jìn)行多維度、快速的下鉆分析。
- 消息隊列:處理后的數(shù)據(jù)流再次寫入Kafka,供下游多個業(yè)務(wù)方訂閱消費(fèi),形成數(shù)據(jù)流閉環(huán)。
- 數(shù)據(jù)服務(wù)層:
- 提供統(tǒng)一的HSF/Dubbo RPC接口或 HTTP API,將實(shí)時數(shù)據(jù)(如商品實(shí)時瀏覽量、賣家信用狀態(tài))封裝成服務(wù),供前端、推薦、風(fēng)控等系統(tǒng)低延遲調(diào)用。
四、 保障千萬級處理的基石:穩(wěn)定性與運(yùn)維
- 端到端精確一次(Exactly-Once):從數(shù)據(jù)源(Kafka)-> Flink計算 -> 數(shù)據(jù)匯(如HBase),通過Flink的檢查點(diǎn)(Checkpoint)機(jī)制和兩階段提交(Two-Phase-Commit)Sink,確保數(shù)據(jù)在任意環(huán)節(jié)故障恢復(fù)后不丟不重。
- 智能監(jiān)控與告警:
- 全鏈路監(jiān)控:對數(shù)據(jù)延遲(Lag)、吞吐量(TPS)、CPU/內(nèi)存使用率、Checkpoint成功率進(jìn)行全方位監(jiān)控。
- 業(yè)務(wù)指標(biāo)監(jiān)控:如實(shí)時GMV是否斷崖式下跌,這可能是數(shù)據(jù)處理鏈路出現(xiàn)問題的信號。
- 自動故障恢復(fù)與降級:當(dāng)某個Flink Task失敗時,自動從最近的Checkpoint重啟;當(dāng)實(shí)時系統(tǒng)不可用時,可降級使用近線數(shù)據(jù)(如幾分鐘前的數(shù)據(jù))作為兜底。
- 資源成本優(yōu)化:通過混部技術(shù)(將在線業(yè)務(wù)和實(shí)時計算業(yè)務(wù)部署在同一批物理機(jī)上,利用其資源使用波谷)、彈性伸縮、計算任務(wù)合并(將多個小Job合并)等手段,在保障性能的同時控制巨大的計算成本。
###
閑魚每秒千萬級實(shí)時數(shù)據(jù)處理的實(shí)現(xiàn),是一個集統(tǒng)一接入、Flink流計算引擎、多層次實(shí)時存儲、標(biāo)準(zhǔn)化數(shù)據(jù)服務(wù)、強(qiáng)悍的穩(wěn)定性保障于一體的系統(tǒng)工程。它不僅僅是一項技術(shù),更是驅(qū)動閑魚業(yè)務(wù)實(shí)時化、智能化的核心引擎。從你點(diǎn)擊一個商品的瞬間,到系統(tǒng)為你推薦下一個可能感興趣的物品,這背后正是這套實(shí)時數(shù)據(jù)處理服務(wù)在毫秒間完成的采集、計算與反饋。隨著實(shí)時數(shù)倉(Real-Time Data Warehouse)和流批一體(Stream-Batch Unification)技術(shù)的成熟,這套體系將向著更簡單、更統(tǒng)一、更智能的方向持續(xù)演進(jìn)。